A few short years ago, the LEGO Group—makers of the iconic locking building-block toys so many parents have stepped on in the middle of the night—was plagued by uncontrolled technology sprawl.
Various business units within LEGO were purchasing redundant licenses for the same technologies, with each team using the technologies for different purposes. Many business units had even established their own computing platforms. The result was unnecessary costs and added complexity.
Michael Schøler, part of a team from Danish consultancy Hinnerup Net, was brought in by LEGO (also based in Denmark) to help sort through the confusion. During a GTC 2012 session Tuesday, he said it was clear at the time that the company needed a unified technology platform that could do everything: facilitate high-end and low-end games, support mobile applications, power the LEGO.com website — you name it.
Henrik Høj Madsen (left) and Michael Schøler (right)
lead the GTC 2012 session
So LEGO turned to NVIDIA. Zeroing in on the CUDA computing platform, the company wanted not only fast rendering of 3D imagery, but also aspired to leverage CUDA to manage critical business functions. Now, three years later, LEGO is running much of its business on the platform.
“We have a proven system that’s working well,” Schøler said during an interview following his session.
CUDA also helped LEGO solve a very specific—and performance-draining—problem. Some 95 percent of the little circular knobs that enable LEGO pieces to interlock are invisible in a finished model, yet a massive amount of the company’s compute power was being sucked up to render those polygons. With Hinnerup Net’s help, LEGO tapped CUDA to purge the invisible polygons in its rendering systems, freeing up computing resources.
Interestingly, one asset LEGO has not yet ported to the CUDA platform is the company’s high-end 3D rendering system, but Schøler said his team is working on that. They’ve developed a proof of concept, and it’s performed well so far. All that’s left is to convince the affected project groups at LEGO to give the green light to make a change.
“We’re trying to convince the business that this is the way to go,” said Schøler. “We’re doing the marketing for NVIDIA.”
You’d be hard-pressed to find an example of technology with the potential to change the course of humanity more than the one provided by behavioral ecologist Iain Couzin at Wednesday’s GTC keynote address.
Couzin, a postdoctoral research fellow at Princeton’s Department of Ecology and Evolutionary Biology, is conducting research that could help humans not only grasp the mysteries of collective animal behavior, but potentially apply that understanding to our own tendencies.
Thousands of attendees packed the keynote hall
for Prof. Couzin’s presentation
Couzin focuses on how and why animals collectively behave the way they do. And he credits CUDA with enabling him to simulate group behavior in ways that were previously impossible.
“The whole way I do science has been transformed by GPU computing,” Couzin told the audience of some 2,500 attendees. “We can spend $500 [for a GPU] and suddenly have more computational power than we could have dreamed of the previous year.”
Not that he’s settling for such an off-the-shelf approach; Couzin is so jazzed by the impact of GPUs on his work that he said he’s working on getting funding to establish a larger, more established GPU-based system. He has his sights set on upgrading the four PCs packed with GeForce and Tesla boards currently used in his lab.
Those little colored dots on the screen represent
a school of simulated fish
One way he’s using GPUs in his research is to simulate the movements of schooling fish – up to 32,000 of them. The GPUs allow him to simulate the impact of certain stimuli on collective behavior. “As a biologist, I want to get inside the heads of these individuals and understand how they communicate and coordinate,” he said.
To illustrate, he provided compelling examples of how he’s accomplishing this. These include:
Applying mathematical equations to understand why fish, when stimulated, naturally form a swirl around an empty center.
Modeling the behavior of fish in at-risk environments, such as the Gulf of Mexico, to determine how a deleterious event, like the BP oil spill, can impact group decision-making.
Using robotic predators to study responses to attacks, with the goal of determining strategies for how to best stimulate, counter or otherwise contend with group behavior.
Studying the impact of how uninformed individuals affect group decision making.
In this last example, he made a startling discovery. Counter to the conventional wisdom that uninformed humans are more easily influenced by extremists, his findings suggest that the presence of those without strong views increases the odds that a group will go with the majority opinion.
Just over the horizon, exascale computing promises 1,000 times more processing power than today’s petascale systems. But there are still many questions about potential challenges and opportunities in the path to exascale.
A panel of experts told GTC attendees Wednesday that developing applications capable of leveraging exascale systems will be key to realizing the benefits of next-generation supercomputers.
“It’s time to get serious about what we’re going to do to make sure we have applications ready for exascale systems,” said panel moderator Mike Bernhardt, publisher of The Exacale Report. He suggested that the race to exascale is likely to be won or lost based on how well the software industry optimizes its applications for massive parallelism.
Panelists wholeheartedly agreed with that premise.
“I’m not worried that we won’t have applications that can run on these platforms,” said Olav Lindtjorn, HPC advisor for oil-services giant Schlumberger. “I’m more concerned about being able to run them in parallel.”
Steve Scott, CTO of NVIDIA’s Tesla business, said he’s skeptical of vendor predictions that apps optimized to run on exascale systems will be available by the end of this decade. “Will apps run on them? Yes. Will they run well? Absolutely not,” Scott said.
Panelists were divided in their opinion about whether new programming models were needed to drive the “exascaling” of applications. Scott said that regardless of which coding tools developers use, the software industry has to find a way to express locality and expose parallelism to take full advantage of exascale systems.
Jeffrey Vetter, distinguished R&D staff member and leader of the future technologies group at Oak Ridge National Laboratory, opined that new programming models will be most important in building robust exascale apps that can contend with system failures, load balancing requirements and the like.
Schlumberger’s Lindtjorn, meanwhile, said he’s not convinced that vendors will have the necessary programming tools ready in time. But, he believes existing tools can be used to achieve the kind of performance levels expected of exascale systems.
The panelists wrapped up the session on an encouraging note. They all agreed that, despite the remaining obstacles on the road to true exascale applications, the HPC community shouldn’t let its enthusiasm for exascale wane.
“It’s a great time to be a computer scientist,” said Vetter. “There’s a lot of exploration going on. The key is to remain optimistic that we’re going to get there.”
Satoshi Matsuoka, a computer scientist from Tokyo Institute of Technology, encouraged applications developers to seek out conversations with computer scientists for answers. “It’s really enjoyable,” Matsuoka said of getting such inquiries. “It gives me interesting problems to solve.”
Scott left attendees with a word of caution: Think big if you have code that you’d like to see running on exascale systems several years from now. “Don’t think about incrementally increasing your parallelism,” he said. “You need to be thinking, ‘Wow, how can I give myself 1,000 times as much parallelism as I have now?’”
Researchers from Tokyo Institute of Technology snagged the first-ever Achievement Award for CUDA Centers of Excellence (CCOE), for their research with TSUBAME2.0.
The team was among three other groups of researchers from CCOE institutions, which include some of the world’s top universities engaged in cutting-edge work with CUDA and GPU computing.
Each of the world’s 18 CCOEs was asked to submit an abstract describing their top achievement in GPU computing over the past year and a half. A panel of experts, led by NVIDIA Chief Scientist Bill Dally, selected four CCOEs to present their achievements at a special event during GTC 2012 this week in San Jose. CCOE peers voted for their favorite, who won bragging rights as the inaugural recipient of the CUDA Achievement Award 2012.
The four finalists – each of whom received an HP ProLiant SL250 Gen8 system configured with dual NVIDIA Tesla K10 GPU accelerators – are described below. Abstracts of their work are available on the CCOE Achievement Award website.
Barcelona Supercomputing Center, OmpSs: Leveraging CUDA for Productive Programming in Clusters of Multi-GPU Systems
OmpSs is a directive-based model through which a programmer defines tasks in an otherwise sequential program. Directionality annotations describe the data access pattern for the tasks and convey the runtime information it uses to automatically detect potential parallelism, to automatically perform data transfers and to optimize locality. Integrating this model with CUDA allows applications to leverage the dazzling performance of GPUs, enabling the same simple and clean code that would run on an SMP to run on multi-GPU nodes and clusters.
Harvard University, Massive Cross-Correlation in Radio Astronomy with Graphics Processing Units
The study of the universe is no easy task. Rather than struggle to build larger and larger telescopes in their challenge to understand our vast universe, Harvard University is using GPU computing technologies to help them create telescope arrays composed of many smaller telescopes. Harvard researchers have developed the Harvard X-Engine code to help integrate data from these types of telescope arrays, with an emphasis on removing data-crunching bottlenecks.
Tokyo Tech, TSUBAME 2.0
Researchers at the Tokyo Institute of Technology have designed and constructed Japan’s first petascale supercomputer, known as TSUBAME 2.0, as well as a series of advanced software and research applications. Such activities have been rewarded with numerous results presented at top academic venues as well as numerous global accolades and press reports. Tokyo Tech highlighted the three core achievements of TSUBAME / CUDA CCOE, but the results are not just limited to them.
University of Tennessee, MAGMA: A Breakthrough in Solvers for Eigenvalue Problems
Scientific computing applications – ranging from those that help analyze how earthquakes propagate through a medium and affect bridges, to those that simulate energy levels of electrons in nanostructure materials – require the solution of eigenvalue problems. The Matrix Algebra on GPU and Multicore Architectures (MAGMA) project aims to develop algorithms that will speed up computations on heterogeneous multicore-GPU systems by at least one order of magnitude.
In a fireside chat at GTC with industry analyst Tim Bajarin, NVIDIA CEO and co-founder Jen-Hsun Huang shared his vision of the future for everything from mobile devices to cloud computing to startup opportunities.
Attendees packed the room to see Jen-Hsun
shake out the future of tech
That vision centers, in part, on the notion that no single approach to technology will ever satisfy all users. Whether people should rely on the cloud or buy a certain device will continue to depend on their particular preferences, he said.
“Over time, what works for the mainstream isn’t going to be desirable for the extremes,” he said. “If everyone in this room has an iPhone, nobody’s special.”
That thought — that heterogeneity will reign more than ever — was sprinkled throughout the discussion. Among his other observations:
On the future of mobile platforms: “We’re early in the development of mobile computing. All of the disparate elements need to be integrated. Everyone’s got an opinion. Microsoft’s got an opinion, Apple’s got an opinion, Oracle’s got an opinion. And the alignment of these interested parties isn’t likely in the early stages of a new market. Give it a little bit of time, and I think the horizontal structure of the industry will become an advantage.”
On Microsoft’s evolving mobile strategy: “It was genius to separate Windows 8 and Windows RT (the recently announced touch-optimized OS). You can’t reposition what a PC is anymore. If they want to create a new computing platform that has virtues in that you can see documents from the PC universe, yet it’s exquisitely designed, you can’t do this in a Windows x86 design. ”
On the future of laptops: “Computers are like cars. Some have two doors, some have four, or five doors. Some have seven seats. It’s different strokes for different folks. You’ll have some that have keyboards, some that don’t. Some will be gesture based, some won’t. The one thing that’s going to be really exiting is that everything is in the cloud.”
On the future of packaged consumer apps: “The idea of buying an application in a box is weird to me. Tomorrow, it’s just wrong.”
After telling the audience where he believes the greatest opportunities for startups lie (the mobile cloud), Jen-Hsun said that legendary Silicon Valley venture capitalist Don Valentine once told him to look for a huge market, assemble great people and develop killer technology. But his advice to young entrepreneurs today took the form of a series of questions: Is this an important problem to solve? Are you the one to solve it? Are you more passionate about it than the competition? Are you more prepared?
“You ask these questions, and so long as the answers are all ‘yes,’ then I’m a big proponent of trying things,” he said.
GTC’s Emerging Companies Summit (ECS) this week showcased nearly three dozen startups from around the world using GPUs to disrupt markets and delight customers. After a day of machine-gun style back-to-back mini-presentations, the event was capped by the announcement of five “One to Watch” awards. Winners raked in more than $20,000 in prizes each.
Presenting companies spanned a range of industries – from BioDigital, which is using 3D visualization of the human body to transform how medical information is communicated, to Zoobe, which lets people quickly share personalized, voice-animated video messages.
The companies shared a resolve to solve hard problems with sophisticated offerings, in many cases with NVIDIA GPUs. Cortexica Vision Systems’ GPU-based platform may put an end to the crossword puzzle-like QR codes using a new type of visual search. Fuzzy Logix aims to make the use of analytics pervasive by embedding it directly into business processes where data already resides.
Cloud computing emerged as a new theme of the event, now in its fourth year. Jeff Herbst, who runs the event for NVIDIA, said ECS’s goal is to build a support network for promising companies, so they can learn from others and be inspired by a wider group of potential customers, partners and investors.
Among the presenting companies were: Rocketick, which is harnessing GPUs to help semiconductor companies to accelerate the chip verification process; Unity Technologies, which makes it simple for anyone to construct their own games full of vivid 3D experiences; and MirriAd, which uses NVIDIA Tesla GPUs to place products in video content, such as TV shows and movies, that are tailored for local audiences and then analyzed for impact.
Winners of the “One to Watch” awards, in addition to BioDigital and Unity Technologies, were:
Elemental Technologies, which provides processing technology that uses GPUs to quickly optimize video and stream it over IP networks
Numira Biosciences, which is working to accelerate the drug development pipeline for pharmaceutical companies by shortening compound discovery and pre-clinical testing processes
Splashtop, which is a provider of a highly rated remote desktop app that streams a PC or Mac to a smartphone with smooth, high-resolution video and audio.
The 150 million-plus miles from Earth to Mars is the least of the challenges facing researchers who are processing images from a rover on the Red Planet.
Consider some others: The rover’s processor is now generations-old technology – the rover was meant to last six months and is going on its seventh year. Mars provides a very “noisy” image environment. There are limited transfer times when an orbiting satellite can send images back to Earth. And the rover’s pint-sized antenna looks like it was fashioned out of a paper clip. Worst of all, there’s no onsite tech support.
But mathematician Brendan Babb, from the University of Alaska at Anchorage, is using GPUs to improve the image compression from data sent by the rover. He uses the CUDA programming language and NVIDIA Tesla GPUs to speed up what is called a genetic algorithm, which mimics natural evolution to derive clearer images from the ones coming from NASA’s Jet Propulsion Laboratory.
A beautiful panorama of Mars Rover “Spirit” from “Troy” (false color)
The algorithm works by pairing neighboring pixels with a random one and then adjusting the random pixel based on whether it incrementally improves the original image. Babb described the algorithm as an “embarrassingly” parallel process, ideally suited to GPU acceleration. He estimates he has been able to achieve a 20 to 30 percent error reduction in subjects like fingerprints and satellite imagery. He’s currently beating the Jet Propulsion Laboratory’s results by a smidgen, and is striving to best it more significantly.
In fact, GPU technology has been so helpful to him that he said he would’ve been satisfied with a 20 percent quicker processing time three years ago. Now he describes himself as “jaded” to the 3-5X speedup he’s achieving, and hopes to reach as much as 10X in the future.
Babb is also encouraging his colleagues at the University of Alaska to learn CUDA because the minimal changes in code required offer a big speedup in results. In the future, he hopes to access Fish, a forthcoming GPU-based supercomputer, to further progress in his work.
Considering NASA completed multiple missions to the moon more than 40 years ago using the technological equivalent of chicken wire and duct tape, landing a robotic lunar rover with modern technology should be a pushover, right?
Not exactly, explained Robert Boehme and Wes Faler, of Part-Time Scientists, during their Day Three keynote address in front of a rapt audience at GTC. A modern mission still has to contend with temperature swings by 300 degrees Celsius and component-destroying lunar sand so fine it can penetrate “airtight” astronaut space suits. Not to mention 10-times the radiation from the sun than we experience on Earth.
Robert Boehme (blue) and Wes Faler (white) talk
about their quest to win the Google Lunar X Prize
The pair is part of a team of more than 100 volunteer scientists, engineers, researchers and students – even veterans of NASA’s Apollo missions – vying to win the Google Lunar X PRIZE, and the $30 million that comes with it. To succeed, the team needs to be the first privately funded team to safely land a rover on the surface of the moon, drive the rover at least 500 meters, and transmit detailed video, images and data back to Earth.
To help ensure its success, the Part-Time Scientists are relying on NVIDIA GPUs to accelerate the mission’s computationally intensive applications. This includes everything from simulating the landing craft’s final orbit and approach, to modeling the rover’s autonomous navigation of the lunar surface in one-sixth the Earth’s gravity – tasks that require hundreds of millions of computing runs to determine possible parameters and their effects.
Once their rover, named Asimov, has reached its destination, the processing and broadcasting of high-resolution video and images back to Earth will require more than 34 trillion floating point operations for the square kilometer the team expects the rover to explore.
Robert and Wes left a surprise for the end of the keynote. They revealed, to the delight of the audience, that Asimov will be a self-driving rover using NVIDIA GPUs to autonomously roam the moon. They then instructed the crowd to check under their seats for an even bigger surprise: one lucky keynote attendee would walk away from GTC 2012 with the Asimov Junior rover prototype.
NASA’s moon missions are famous for having helped bring into existence new technologies, like Teflon and Tang. Four decades on, NVIDIA’s GPU technology is helping volunteer rocket scientists every step of the way on a journey back into space.
The third GPU Technology Conference (GTC) ended Thursday much as it began – with a jam-packed keynote session, standing-room only break-out sessions and a small galaxy of schmooze-fests along the sidelines.
Indeed, the final sessions were as crowded as those on the morning of Day One.
NVIDIA used the event – which is designed to nurture the GPU ecosystem – to unveil some news of its own. It introduced two new Tesla processors based on next-generation Kepler technology architecture, one of which has more than 7 billion transistors. And it announced that it’s taking the GPU into the cloud with two initiatives, the VGX platform for enterprises to deliver virtualized desktops to any device across their network and the GeForce Grid for the delivery of flawless online gaming.
Another way of looking at GTC is by the numbers. The conference….
Drew nearly 3,000 attendees from 54 countries
Offered 340+ conference sessions in 34 disciplines
Displayed 120 academic posters about CUDA applications
Featured 100+ HPC-focused exhibitors
And, was filled with enough hyphenated, multi-syllabic Latinate words to baffle all but the uninitiated…
If you missed this year’s event, you can catch up on the GTC blog posts, here: http://blogs.nvidia.com/tag/gtc12. Watch the video below, for NVIDIA VP Ujesh Desai’s wrap-up from the show.
Join us next year, March 19-22, for GTC 2013. We’ll be right back here at the San Jose Convention Center.
Nearly three dozen companies participated in the Emerging Companies Summit, held during NVIDIA’s GPU Technology Conference in May. Below is one in a series of company profiles showcasing how startups are innovating with GPU technology.
Since its founding five years ago, Splashtop has been delivering quick access to the online world for remote users.
More than 7 million people worldwide use the San Jose, Calif.-based company’s apps on their mobile devices to remotely – and inexpensively – access their PCs or Macs, and associated programs, data, applications, movies and games.
One customer, Orlando Tech’s video department, used Splashtop in their work to fashion an inexpensive yet versatile and portable movie camera using a tablet. Students there filmed an actor in a 3D sensor suit, converted the live action into animation and then edited it with the latest real-time animation software – all using the touch interface of the tablet. What normally would’ve required expensive, cable-connected cameras and sitting at a deskbound workstation was done on the fly and at a fraction of the cost using Splashtop.
Innovations like this helped Splashtop snag a “One to Watch”award at the Emerging Companies Summit 2012. The company is also a two-time “Best of CES” winner. Their apps are consistently highly ranked, even besting Angry Birds download numbers at times, according to Cliff Miller, Splashtop’s chief marketing officer.
When screen-scraping to mobile devices, speed is the name of the game and Splashtop customers using NVIDIA GPUs hold an edge. Visitors to the Splashtop booth at the GPU Technology Conference got a chance to play graphics-intense gaming titles Skyrim and newly released Diablo III.
The demo showed how Splashtop could stream the games – in hi-res and with no lag – from a GeForce GPU-powered PC onto a Tegra 3-based ASUS Transformer Prime tablet via Splashtop’s Gamepad THD app. With smartphones or tablets powered by NVIDIA GPUs, users experience very low latency, so videos play smoothly and touch interfaces are super-responsive – up to 60 frames per second.
Another grateful customer from Japan described to Miller how Splashtop had provided the remote desktop technology he had long been looking for. The man zipped his tablet into a plastic bag and then took it into his bath so he could watch a movie, play games or even get some work done, all while enjoying a relaxing soak. Talk about making a splash!
A new kind of open gaming device needs a new kind of development process.
Rather than being secretive about SHIELD and what it can do, we decided to bring gamers in on the conspiracy, announcing our plan to bring a portable gaming device with console-class controls and a high-def 5-inch screen to market in January at the Consumer Electronics Show.
Most of all, we wanted this device to be open and provide the best possible experience—whether you’re playing Android or PC games, or enjoying your favorite movies, music, and other apps on the go.
Since then, we’ve put SHIELD in the hands of thousands of gamers. Some have been professional press. Others have been inside our own company. But most have been people like the tens of thousands who streamed through our booth at PAX East and E3.
And their reactions have been more than just positive.
They’ve helped us build a better product. Feedback from gamers is why SHIELD’s triggers have the perfect throw length. Why SHIELD’s buttons have just the right amount of give. Why SHIELD’s thumb sticks are so satisfying to flick. Why playing games on SHIELD’s pure Android software feels so slick.
The result: while SHIELD isn’t available until June 27th – we’re making that official today – it’s already grabbed awards by the fistful – including dozens of ‘Best of Show’ awards at CES, Computex and E3.
Now it’s time for one more change.
We’ve heard from thousands of gamers that if the price was $299, we’d have a home run.
So we’re changing the price of SHIELD to $299.
If you’ve already pre-ordered SHIELD, you’ll be charged the new, lower price. You will only be charged $299 when the product ships.
We want to get SHIELD into the hands of as many gamers as possible.
That’s because we think they’ll have the same reaction to it as thousands of gamers already have: joy.
Virtually all those attending this week’s 2013 International Supercomputing Conference (ISC) in Leipzig, Germany, would agree that there’s an insatiable demand driving the race to exascale computing.
Where they would disagree is what it will take to get there.
NVIDIA’s Chief Scientist, Bill Dally, tackled this issue in the ISC conference keynote address he delivered at the big event, entitled “Future Challenges of Large-scale Computing.”
Presenting to some of the high performance computing (HPC) industry’s foremost experts, Dally outlined challenges the industry needs to overcome to reach exascale by the end of this decade.
It boils down, in his view, to two major issues: power and programming.
It’s About Power, Forget Process
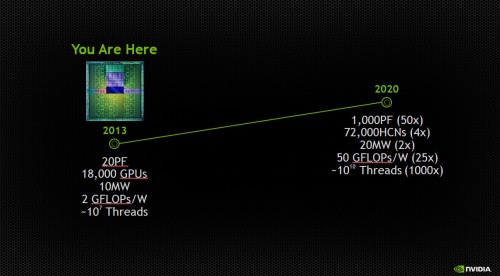
Theoretically, an exascale system – 100 times more computing capability than today’s fastest systems – could be built with only x86 processors, but it would require as much as 2 gigawatts of power.
That’s the entire output of the Hoover Dam.
On the other hand, the GPUs in an exascale system built with NVIDIA Kepler K20 processors would consume about 150 megawatts. So, a hybrid system that efficiently utilizes CPUs with higher-performance GPU accelerators is the best bet to tackle the power problem.
Still, the industry needs to look for power efficiencies in other areas.
Reaching exascale, according to Dally, will require a 25x improvement in energy efficiency – 50 gigaflops (or billion floating point operations per second) per watt vs. the 2 gigaflops per watt from today’s most efficient systems.
And, contrary to what some believe, manufacturing process advances alone will not achieve this goal.
At best, this will only deliver about a 2.2x improvement in performance per watt, leaving an energy efficiency gap of 12x that will need to be reached by other means.
Dally believes that a combination of more efficient circuit design and better processor architectures can help close the gap – delivering 3x and 4x improvements in performance per watt, respectively.
Dally’s engineering team at NVIDIA is exploring a number of new approaches, including utilizing hierarchical register files, two-level scheduling, optimizing temporal SIMT, and other advanced techniques – all designed to maximize energy efficiency in every way possible.
Programming is a “Team Sport”
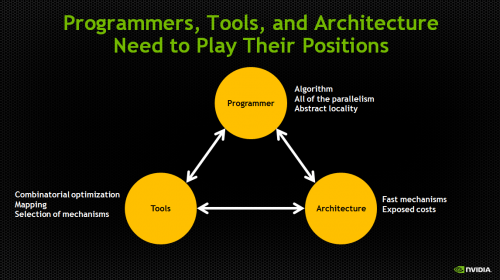
Dally says that second big challenge to overcome is making it easier for developers to program these large-scale systems.
This is not to say that parallel computing is hard. Rather in Dally’s view, parallel programming is easy…but “we make it hard.”
He explained that programmers, programming tools and the architecture each need to ‘play their positions.’
For example, programmers should focus on designing better algorithms – and not worry about optimization or mapping. Leave that to the programming tools, which are much more effective at these types of tasks than humans.
And the architecture – well, it just needs to provide the underlying compute power, and otherwise “stay out of the way.”
On top of this, Dally notes that tools and programming models need to continue improving, making it even easier for programmers to maximize both performance and energy efficiency.
Potential improvements Dally is investigating in this area include using collection-oriented programming methods, which will continue to make the process of programing large-scale machines quicker and easier.
By focusing on these areas, Dally is confident that exascale computing is within our reach by the end of the decade.
In a workplace where water-cooled, overclocked PCs aren’t just tolerated, but encouraged…. where employees stockpile automatic Nerf guns and wield two-handed Nerf broadswords in meetings…where flat-screen encrusted cubicles loom like something out of the ‘Matrix’… Chris Holmes’ corner at NVIDIA’s headquarters sticks out.
It’s here where two great geek cultures — Lego and Star Wars — intersect in such monumental fashion that it’s become a navigational aid, the quick-witted engineering manager explains as he sits at his cube with his feet dangling in an inflatable pool filled with colorful rubber balls.
That’s because if you’re going anywhere on the first floor of his building, all you have to do is look for the collection of enormous Star Wars Legos space vessels perched atop Holmes’ cube to orient yourself. It’s a collection worth hundreds, perhaps thousands, of dollars.
A fully-operational battle station: the collection began in college with this 3,499-piece Death Star.
“I’ve had a frightening number of people who drop by my cube just to say ‘hi,’ to either see the Legos or to, um, show their children,” Holmes says. “It certainly has made it easy to find me and it’s a great conversation starter.”
Chris, 32, who sports a youthful mop of curly black hair, isn’t shy about being a geek. ”I’m the king of the geeks,” he says cheerfully. Chris founded NVIDIA’s board games club and helps lead its in-house StarCraft team.
And this king is happy to hold court to discuss everything from his taste in science fiction (Dan Simmons’ Hyperion cantos, which he keeps on his desk, are perhaps “the best science fiction I’ve ever read”) to his passion for Babylon 5.
Don’t be fooled by his easygoing manner, however. Holmes has won infamy inside NVIDIA as a prankster, even if he’s not willing to disclose the details in full at this time.
“I have been lucky in that many targets have not been brave enough to get even,” Holmes says, cryptically. “Even though I did end up with a Christmas tree in my cube… I may, or may not, have deserved it,” he adds.
The inflatable pool filled with plastic balls is a leftover from one such prank.
Method to the Madness
But it’s his collection of Star Wars Lego ships that has turned cubicle C/612L into a landmark. And, like any great collection of art, wine, or furniture, there’s a logic to it.
From left to right atop Holmes’ cube sit a huge 3,449-piece Lego model of the Death Star, with a tiny to scale representation of a Super Star Destroyer beside it.
Then there’s a three-and-a-half foot long, 3,152-piece model of the Super Star Destroyer, with a tiny to-scale representation of a Star Destroyer beside it.
And then, of course, there’s another 3,104-piece model of a Star Destroyer with a tiny to-scale representation of the blockade runner, from ‘Star Wars IV: A New Hope,’ beside it.
Some collect wine, others collect oil paintings. Chris’ collection is much more interesting.
This is the core of the collection. There are a number of other pieces, too — grace notes in this symphony of space-faring super-structures — including the Imperial Walker from “Star Wars V: The Empire Strikes Back,” and the Imperial Shuttle that first appeared in “Star Wars VI: Return of the Jedi.”
It’s a collection Holmes has spent nearly a decade assembling, even if there are some shady spots in the provenance of one or two pieces. He acquired the first piece — the Death Star — while studying Computer Engineering and Computer Science at Georgia Tech, about seven years ago.
“I managed the housing staff and I convinced them to let me buy one so that the residents could put it together,” Holmes says. “And then I raffled it off. I may have won my own raffle. There may or may not have been rigging.”
The other pieces — all limited editions — were purchased, chiefly used. Like any savvy collector, Holmes knows how to stretch his funds to add smartly to his collection (although the Imperial Shuttle, the latest addition to his display, was purchased new for his birthday).
Holmes says he sees no need to add to his collection. In part, because he’s run out of space. Asked if he could have anything in the world made of Legos, he begs off.
“I’ve kind of got it, actually, these are my favorite ships, I can’t think of anything else that would look as good — I love Babylon 5 and the paraphernalia associated with it — but the artistic style would not go with Lego,” he says. “I’m good.”
Never say never, however. If you’re a bit of a geek yourself, you’ve surely noticed the missing piece in this collection.
It is, of course, the Lego model of the Blockade Runner featured in the opening scene of ‘A New Hope,’ released in 2001, and now rarely seen in the wild.
Piecing Things Together
If Holmes ever obtains it, he won’t be the only one to share in the fun.
“I’ve never built one, not solo, not even close, because I just do it with people,” Holmes says of his Lego sets. “I just bring these models to board game night and six of us descend on these pieces and put the thing together in about four hours.”
And that, of course, is the real purpose of this collection. Chris isn’t putting plastic pieces together. He’s connecting people to one another.
Microsoft is introducing a major revamp to Windows RT at its annual BUILD conference this week.
Dubbed Windows RT 8.1, this is no mere update. Windows RT 8.1 streamlines many aspects of the RT experience and adds new features such as built-in Outlook, the ability to search across different apps, and improvements for enterprise users such as NFC printing, better VPN support, support for Microsoft’s Workplace Join, and greater support for services offered by mobile device management vendors.
The update paves the way for new Windows RT devices running on NVIDIA’s Tegra 4 mobile processors. Microsoft’s VP of Planning, Mike Angiulo, recently commented on the implications, stating “NVIDIA’s Tegra 4 processors will put Windows on more powerful, more portable devices than ever before.”
Devices powered by Tegra 4 are going to scream through web browsing, briskly handle multiple apps and instantly switch into high fidelity gaming. All while delivering the portability and battery life ARM-based processors are known for, and on the industry’s most secure Windows platform.
Rene Haas, our VP of Computing, echoed this excitement recently, saying, “The upcoming release of Outlook for RT will enhance the capabilities of RT devices, fulfilling the Windows RT promise of work and play, on one device.”
We can’t wait to show the world the new Windows RT 8.1 experience, especially on Tegra 4 – the fastest mobile processor NVIDIA has ever delivered. You can download the Windows RT 8.1 Preview through the Windows Store now. Microsoft has stated the final product will be available later this year.
We’re grateful for all the enthusiasm that’s been expressed for SHIELD, our new portable gaming device. And we’re eager to get it into your hands.
But we won’t do that until it’s fully up to the exacting standards that NVIDIA’s known for. And some final quality-assurance testing has just turned up a mechanical issue that we’re not happy with.
So, while we announced last week that SHIELD will go on sale this Thursday, we’ve taken the hard decision to delay shipping until next month.
The issue relates to a third-party mechanical component, and we’re working around the clock with the supplier to get it up to our expectations.
We apologize to those who have preordered SHIELDs and to all those who are waiting for them to go on sale. But we want every SHIELD to be just right.
We’ll let you know when we have an exact shipping date in July. We think it will be worth the wait.
[Editor's note: This story has been updated with direct download links to drivers.]
NVIDIA released WHQL-certified GeForce drivers today for Windows 8.1 to coincide with the availability of the Windows 8.1 Release Preview from Microsoft.
You can install the new GeForce driver version 326.01 for Windows 8.1 from Windows Update after you install the Release Preview.
NVIDIA has long been committed to working with Microsoft to ensure the best possible Windows experience for GeForce users. Our close working relationship with Microsoft allows us to provide WHQL-certified GeForce drivers via Windows Update on Day 1 for key milestones such as this Release Preview.
It’s a substantial effort that requires hundreds of man years of engineering time and thousands of hours of testing and certification, but it’s essential to ensure optimal performance and stability for the world’s largest gaming and productivity platform.
Henry Moreton, Ph.D., is a Distinguished Engineer in the architecture group at NVIDIA. He holds over seventy-five patents in the areas of optics, video compression, graphics, system and CPU architecture, and curve and surface modeling and rendering.
Tiled Resource support in Direct3D was introduced today by Microsoft at its annual Build developer conference.
Tiled Resources are a major advance in application flexibility in managing memory, and I’m excited to think about the applications this will open up.
Before Tiled Resources, all memory surfaces in Direct3D had to be fully physically resident in DRAM. Tiled Resources are different – they are memory resources whose constituent pages (tiles) may be optionally populated with corresponding physical memory. Microsoft has created a standard hardware interface to what was previously a software-only technology, which will mean a more powerful, efficient generalization of earlier texture-only technologies.
To illustrate the usefulness of Tiled Resources, Microsoft shared three demonstration applications all running on NVIDIA GPUs. The first two illustrated the use of Tiled Resources to support view-dependent streaming of texture detail.
Image may be NSFW. Clik here to view.In the first, Microsoft took the audience to a point high above Mars, and then zoomed down to expose the detailed crags and crannies of the rocky red planet’s surface. In the application, the surface of the planet is textured with six sets of 16K mipmapped textures. By taking the current viewpoint into account, the application need only populate a tiny fraction of these textures.
Image may be NSFW. Clik here to view.In the second demo, provided by Graphine Software, Microsoft showed a futuristic plane flying over a highly detailed landscape. The viewer flew high and low, yet the full richness of the land below remained visible throughout.
In both, Tiled Resources are used by the developer to only allocate memory necessary for the current view, though the hardware renders from enormous textures.
This slight-of-hand greatly simplifies the developer’s task, in turn allowing the hardware to automatically filter the texture as though all of the texture were present. The end result is lower development time, a higher fidelity image, greater performance and less power consumption.
Image may be NSFW. Clik here to view.In a third demo illustrating another powerful use of Tiled Resources, Microsoft showed a program developed by our content technology group. It showed a power plant filled with fine shadows that dynamically shift to reveal the detailed environment.
In this example, an enormous shadow depth map is used to precisely compute the shadows in the scene.
To avoid the allocation of a prohibitive amount of memory, Tiled Resources are used to allocate only the memory required to compute the shadows for the current view, a tiny fraction of the total.
The residency map, on the left, depicts the allocation map; the black region represents high resolution, and shades of represent progressively lower resolutions of the shadow hierarchy.
These demos are excellent highlights of the power of Tiled Resources. By working in collaboration with Microsoft, our NVIDIA team has been able to influence the design of Tiled Resources and deliver a solid driver that taps into the huge NVIDIA installed base. There are over 90 million NVIDIA GPUs capable of supporting Tiled Resources. For developers, that means an enormous, instant installed base for a powerful new feature. I’m really looking forward to seeing how developers take advantage of this newly available capability.
Representing Africa for the first time in an international computing challenge, they lacked competition-tested experience. They also were the youngest of the eight teams, made up only of undergrads.
And worse, they couldn’t access their cluster until a day after they arrived at ISC, while the other seven teams had been practicing on their systems well ahead of time.
But once the dust settled and scores were tallied, CHPC stood alone at the top, earning the coveted “Overall Championship Award” in the competition.
Their secret sauce: NVIDIA GPU accelerators.
The Edge Goes to GPU Accelerators
Dan Olds, principal analyst with Gabriel Consulting and creator of the new Student Cluster Competition website, said that NVIDIA GPU accelerators made quite a difference:
“Like all the other teams, South Africa used accelerators to give their cluster a turbocharged punch. While some teams used Intel Phi co-processors, team South Africa went with eight NVIDIA K20 cards, which seemed to do the trick.”
Using an eight-node Dell PowerEdge system with eight NVIDIA Tesla K20 GPUs – the highest performance, most efficient accelerators ever built – Team South Africa achieved a runaway victory for the overall competition.
In the competition, teams were scored on how well their cluster performed on a number of real-world applications including GROMACS, a molecular dynamics package, MILC, a quantum chromodynamics app, and WRF, a widely used weather research and forecasting application.
There were also two ‘mystery’ applications that were disclosed on the day of the competition: the AMG numerical analysis application and the CP2K molecular simulation package.
Center for High Performance Computing (CHPC) team from South Africa.
Together, these performance marks accounted for 60 percent of South Africa’s overall score, with the rest coming from interviews with event judges.Team South Africa entered the competition as big underdogs, and emerged as the big victors.But they weren’t the only ones to benefit from GPUs.
All Accelerators are not Created Equal
Olds, in a recent blog post, discussed the dramatic increase in the use of accelerators by the winning student cluster teams:
“Everyone is using accelerators this year, either NVIDIA GPUs or Intel Phi co-processors. We’ve seen accelerator use increase steadily since they made their first appearance in 2010.”
In addition to South Africa, GPUs powered the top four systems earning the highest Linpack scores, soundly beating off other teams that used Xeon CPUs or Xeon Phi accelerators:
Team Huazhong, China — 8.455 TF
Team Edinburgh, UK — 8.321 TF
Team Tsinghua, China — 8.132 TF
Team South Africa — 6.371 TF
GPU accelerators gave these and other teams a competitive edge by delivering the highest performance per watt, which is critical given the competition’s 3,000 watt power cap.Fifth-Straight Win for GPUsThis is the fifth straight time that GPU-accelerated systems have won the “Overall Award” in the Challenge, as well as achieved the top Linpack scores. In addition to ISC 13, GPU-equipped teams came out on top at ISC 2012 and Supercomputing Conference 2011 and 2012, and the top three Linpack-winning systems in the first-annual Asia Student Cluster Challenge April 2013 used Tesla GPUs as well.Next up: the student competition at the SC13 conference in Denver this November. Will teams using GPU accelerators reign supreme again? Place your bets, and let us know what you think.
Like a one-man band for moviemaking, Autodesk Smoke video editing and effects software running on NVIDIA Quadro GPUs empowers digital artists to play the roles of writer, director, editor and post-production specialist – all in one.
Bringing to mind harmonicas, hi-hat cymbals and tambourines in one glorious cacophony might not be most people’s idea of a good thing when it comes to movies. But check out the amusing, action-filled short film by Jeremy Hunt below – it may change your mind.
The 8-minute short, titled Fix It In Post, tells the story of an ordinary guy whose day takes some extraordinary turns. It was created to showcase the capabilities of Autodesk Smoke 2013, which itself was used to make the film. Smoke integrates high-end visual effects into nonlinear workflows familiar to digital editors.
The NVIDIA Quadro K5000 for Mac and Quadro 4000 for Mac, the world’s most powerful professional graphics cards, significantly accelerate the performance of the visual effects tools on Smoke used for compositing, color correction, motion graphics and more.
The technology combo allows digital video editors and producers to turn their unique vision into visual reality. They can decide what a character should say, what a shot should look like, how a scene should play out, how a set should be lit, etc. And, it breaks down the barriers of cost and complexity that have traditionally hindered small film productions.
Plus, digital editors don’t have to waste time exporting files and moving data from application to application. With Smoke on Quadro, time-consuming multiple-application workflows are replaced by a single, efficient application to deliver new creations quickly. That should be music to any editor’s ears.
Ever wanted to see what your body looks like on a molecular level? How each atom interacts and interlocks with others, before breaking off and tumbling to the ground? Or what your portrait would look like if painted by Vincent Van Gogh?
Well, now you can – sort of. Two works of electronic art powered by NVIDIA’s CUDA technology now on display at the Boston Cyberarts Gallery as part of the Collision19:COmpress/DECompress new media arts show will help you see yourself in new ways.
The first, Everything is Made of Atoms– created by James Susinno and Mark Stock — puts an image of its viewers on a screen, an image composed of thousands of small particles constantly falling and regenerating, showing the complex relationship between a body and its constituent parts.
CUDA Saves the Day
Susinno and Stock — an artistic duo known as Axes — used CUDA to generate imagery that wouldn’t be possible otherwise. Early versions of Atoms relied on CPUs alone to do the work, but the results didn’t have the detail or frame rate necessary to support a vivid, expressive interface.
When they decided to port the underlying fluid simulation to CUDA, the duo was surprised by the tenfold increase in speed, which produced more particles and a higher frame rate. CUDA turned what had been thin, flimsy visuals into a rich, captivating experience.
A digitized viewer stands in a pool of his own shed atoms.
Powered by a desktop computer running on a GeForce GTX 660Ti GPU, Atoms’ depth-sensor returns data related to the viewer’s image, depth, silhouette and skeleton, which the C++/OpenGL/CUDA application tracks and then translates into a geometrical display on the screen.
A direct N-body vortex methods solver, written in CUDA, controls the real-time fluid simulation, and calculates the position and orientation of the fluttering particles. The GPU powering the display not only performs the vortex dynamics simulation, but also renders the tens of thousands of particles and an 8,000 by 8,000 ground texture to a an ultra-high definition monitor at 30 frames per second, generating a visual of a human being shedding atoms.
Collision19:COmpress/DECompress, a new media art show being held at Boston Cyberarts Gallery featuring Atoms and Dial,runs from June 14 to July 28.
No Smartphones Necessary
The second Boston Cyberarts Gallery display to use CUDA was created by Robert Gonsalves, who describes his Dial-A-Style piece as an algorithmic portrait studio. Dial is an interactive video installation that allows visitors to create a digital self-portrait in a variety of artistic styles, from Vincent van Gogh-inspired Impressionism to comic book fueled Anime.
The visitor starts by spinning the Dial-A-Style wheel (below). The wheel might stop at four artistic styles – Impressionism, Cubism, Pointillism or an Anime theme. The wheel can also stop in between styles, resulting in a hybrid portrait.
Once the wheel stops, optical detectors send a signal to the computer, which triggers a webcam to take a picture of the visitor. The computer then runs the selected algorithm to create a stylized painting, which is displayed on a screen. If the viewer likes the portrait, he or she can upload it from the artistic display and then download it for themselves from www.robgon.com.
The software powering Dial is written in C++ and uses CUDA kernels to solve quadratic equations as part of eigenanalysis to estimate local gradient orientation, using smoothed structure tensors. This technique, combined with the use of extended difference-of-Gaussians (XDoG) image processing techniques, creates the painterly images. And, the whole installation runs on a GeForce 9600 GT graphics card.
In creating the algorithmic self-portrait generator, Gonsalves says he hopes visitors will gain insight into the perspectives of familiar visionary artists. By experimenting with different kinds of algorithmic selfies, viewers can better understand the emotional responses each one of these art forms might prompt.
We got excited by these artists’ works because they took advantage of scientific computing and high-performance graphics methods to create novel pieces of art. Let us know in the comments section if you’ve ever used high-performance graphics or advanced computing for creative purposes.